
티스토리 뷰
1️⃣kafka 배경
Kafka는 원래 LinkedIn에서 개발하고 나중에 Apache Software Foundation에 기부한 오픈 소스 분산 스트리밍 플랫폼이다.
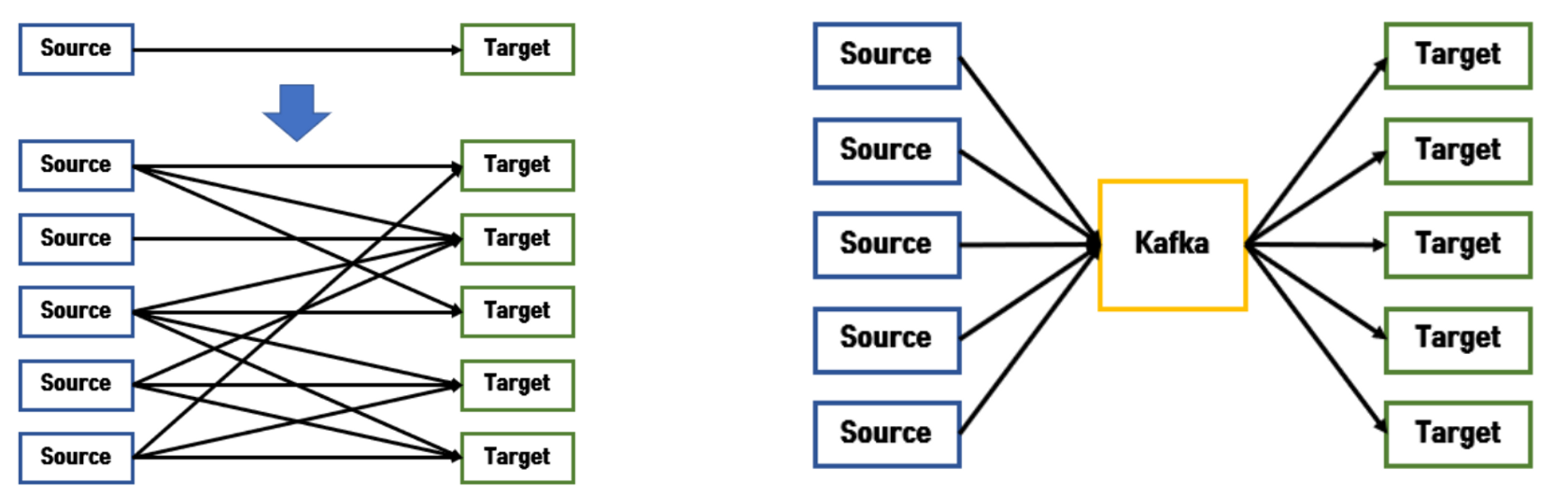
이전의 어플리케이션 간 연결이 복잡해져 서로 영향을 주게 되던 구조에서, 데이터를 중앙집중화 하는 시스템을 만들었다.
대규모, 높은 처리량, 실시간 데이터 스트리밍 및 처리를 처리하도록 설계되었습니다.
2️⃣기본 개념
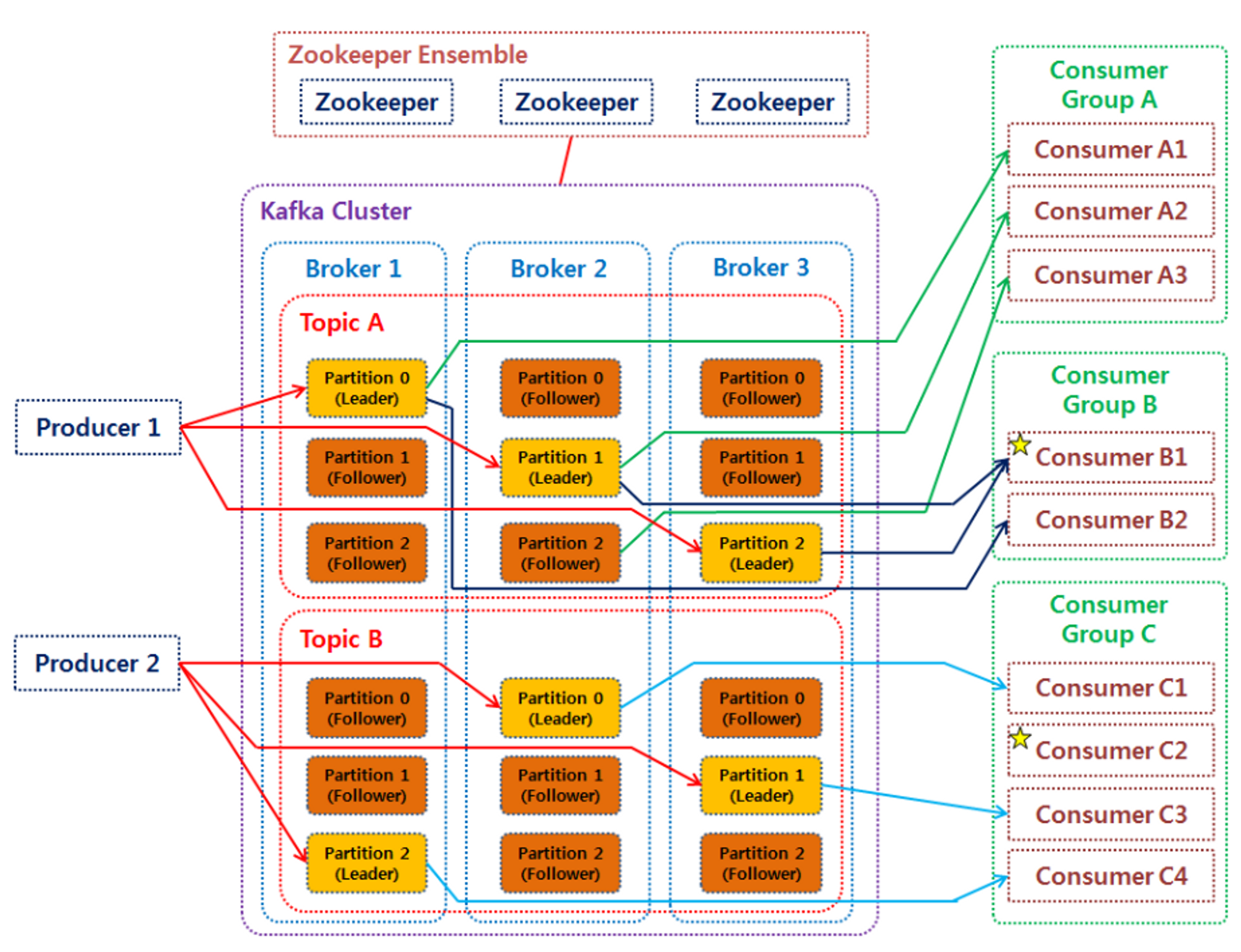
TOPIC
Kafka는 메시지의 범주 또는 피드인 토픽으로 데이터를 구성하는데, 각 메시지는 특정 토픽에 추가된다.
병렬 처리 및 확장성을 허용하기 위해 항목을 파티션으로 나눌 수 있다.
PRODUCER
Kafka 토픽에 메시지를 게시하는 애플리케이션 또는 시스템.
특정 토픽에 메시지를 쓰고 쓸 파티션을 선택하거나 Kafka가 파티션을 자동으로 할당하도록 할 수 있다.
CONSUMER
토픽에서 메시지를 읽는다.
하나 이상의 토픽을 구독하고 작성된 순서대로 메시지를 소비할 수 있다.
각 컨슈머는 각 파티션에서 마지막으로 소비된 메시지의 위치인 자체 오프셋을 유지한다.
BROKER
브로커라고 하는 서버의 분산 클러스터에 의존한다.
브로커는 여러 노드에서 메시지 데이터를 저장하고 복제하는 일을 담당한다.
게시-구독 메커니즘을 처리하고 프로듀서와 컨슈머 간의 조정 및 통신을 제공한다.
PARTITION
토픽은 병렬성과 확장성의 기본 단위인 파티션으로 나뉜다.
각 파티션은 순서가 있고 변경할 수 없다. 즉, 파티션 내의 메시지는 순서를 유지하고 한 번 작성하면 수정할 수 없다.
파티션을 사용하면 수평적 확장이 가능하고 여러 컨슈머가 토픽에서 동시에 읽을 수 있습니다.
REPLICA
- Kafka는 데이터 복제를 통해 내결함성(시스템의 일부가 고장 나더라도 나머지는 올바로 작동하는 능력)과 고가용성(서버와 네트워크, 프로그램 등의 정보 시스템이 상당히 오랜 기간 동안 지속적으로 정상 운영이 가능한 성질)을 제공한다.
- 각 파티션에는 여러 레플리카가 있을 수 있으며 각 레플리카는 다른 브로커에 저장된다.
- 레플리카는 브로커가 실패하는 경우 다른 복제본이 데이터 손실 없이 인계할 수 있도록 한다.
OFFSET
- Kafka는 특정 파티션에서 소비자의 위치를 나타내는 오프셋 개념을 유지한다.
- 컨슈머는 오프셋을 커밋하여 자신의 위치를 제어할 수 있으므로 장애가 발생하거나 다시 시작할 경우 중단한 지점부터 consume을 재개할 수 있다.
STREAM AND STREAM PROCESS
- Kafka는 Kafka Streams API를 통해 스트림 처리도 지원하기 때문에, 이를 통해 개발자는 데이터 스트림을 처리하고 파생된 스트림 또는 집계를 생성할 수 있는 확장 가능하고 내결함성이 있는 실시간 애플리케이션을 구축할 수 있다.
2️⃣KAFKA 내결함성과 실시간성
분산 아키텍처
데이터 및 처리가 여러 브로커에 분산된 시스템으로 구축되어있어 여러 브로커에 걸쳐 데이터를 복제하여 내결함성을 제공합니다.
브로커가 실패하면 다른 브로커가 데이터 손실 없이 책임을 맡을 수 있기 때문에 이러한 분산 특성은 장애에 대한 고가용성과 복원력을 보장한다.
복제 및 내구성
Kafka는 여러 브로커에서 데이터 복제를 허용한다.
각 토픽에는 여러 파티션이 있을 수 있으며 각 파티션에는 여러 복제본이 있을 수 있다.
복제는 내결함성과 내구성을 제공하여, 브로커나 디스크에 오류가 발생하면 다른 브로커의 복제된 데이터를 사용하여 메시지 손실 없이 처리를 계속할 수 있다.
지속성
Kafka는 브로커나 서버가 충돌하더라도 디스크에 데이터를 유지하여 내구성을 제공한다.
Kafka 토픽에 기록된 메시지는 커밋 로그 형식으로 저장되어 빠른 쓰기와 효율적인 디스크 활용이 가능하다.
그러므로 오류가 발생하는 경우 데이터가 손실되지 않도록 보장하기 때문에 지속성을 가진다.
확장성 및 병렬성
Kafka의 아키텍처는 수평적 확장성과 병렬 처리를 지원한다.
토픽은 여러 소비자가 메시지를 동시에 처리할 수 있도록 파티션으로 나뉘기 때문에, 각 파티션을 독립적으로 처리할 수 있어 높은 처리량과 리소스의 효율적인 활용이 가능하다.
오프셋 및 메시지 재생
Kafka는 소비자가 읽은 파티션의 위치를 나타내는 각 소비자에 대한 오프셋을 유지하고, 이 오프셋 추적을 통해 소비자는 메시지를 재생하거나 장애 발생 시 중단한 위치부터 처리를 재개할 수 있다.
내결함성 처리가 가능하고 누락된 데이터가 없도록 보장한다.
실시간 처리
Kafka는 대기 시간이 짧고 실시간에 가까운 처리 기능을 제공한다.
처리량이 높고 초당 많은 양의 메시지를 처리할 수 있다.
이렇게 Kafka는 지속적인 데이터 수집 및 처리를 허용하므로 실시간 스트리밍 애플리케이션에 적합하다.
스트림 처리 및 통합
Kafka는 Apache Flink, Apache Spark 및 Kafka Streams와 같은 스트림 처리 프레임워크와 잘 통합된다.
이러한 프레임워크를 통해 개발자는 Kafka 위에 실시간 데이터 처리 파이프라인을 구축할 수 있다.
집계, 변환 및 복잡한 이벤트 처리 기능을 제공하여 실시간 분석 및 통찰력을 가능하게 한다.
'정리노트 > 기타' 카테고리의 다른 글
| Elasticsearch 마이그레이션 수행기 (0) | 2025.04.19 |
|---|---|
| Springboot 마이그레이션 수행기 (0) | 2025.04.12 |
| 네트워크 기초 (0) | 2023.05.31 |
| ETL 프로세스 / 하둡 / 스파크 (0) | 2022.09.13 |
| Elastic Search (+ ELK 스택) (1) | 2022.09.13 |
